Matt Bruenig at the People’s Policy Project (PPP) published a post at the end of September, looking at 2016 data for family net worth as reported by the Survey of Consumer Finance (SCF). Using the 2007 and 2016 waves of the survey, Bruenig grouped family net worth into percentiles, and took the difference between each point. Bruenig broke the results down by race/ethnicity, but generally speaking, aside from the wealthiest Americans, most families still haven’t recovered to their pre-recession level of household net worth. Bruenig presented the results as line graphs, which didn’t strike me as particularly problematic when I read the post, but a friend pointed out that the tweet announcing the post had stacked up a bunch of crabby comments.
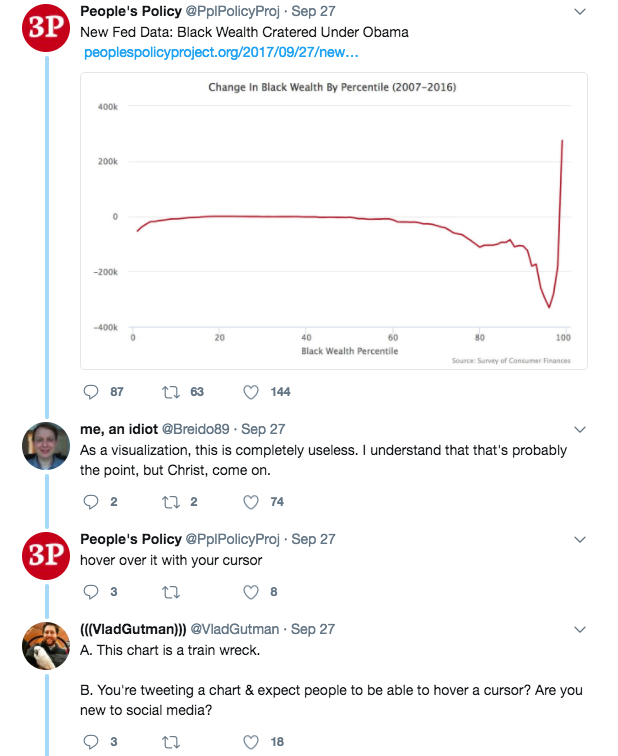
A fair amount of the responses seemed to be complaining that line graphs should be restricted to displaying a quantitative variable against an axis representing time. This seems to be an argument based on convention, and I don’t really find it persuasive. The quantity we’re interested in is the distance between the baseline (0) and the mark indicating the estimate at a given percentile. Bruenig could’ve represented the values as bars, but the viewer still needs to look at the axis labels to make sure they’re reading the graphic correctly. Additionally, bars take up a lot of space/ink on a plot, and feel a little heavy-handed with so many points/percentiles.
However, buried in the responses, there were a few substantive questions that could be addressed with some additional data. Criticisms largely centered on the choice of two particular waves in the SCF: 2007 and 2016. Many folks commented that Barack Obama wasn’t in office at the time of the first wave, and that any observed declines need to account for the financial crisis that would kick into effect between 2008-2009. My read was that Bruenig’s choice of these two points was meant to provide a sort of pre/post-Obama comparison, providing a really zoomed-out view over two terms. I also don’t think this overlooks the recession at all. Given that the recession occurred during Obama’s presidency, it seems weird to suggest that the policies his administration pursued or supported weren’t colored by the crisis. The extent to which a president can truly affect the course of the economy (or within a certain period of time, such as the length of a presidential term) is a bigger question, and seems unlikely to be answered with the SCF alone. Based on these datasets, which represent only one method of looking at net worth, we’re posing the basic question of how different racial/ethnic groups in the US fared under Barack Obama’s presidency. This is different from claiming that Obama’s administration is solely responsible for an incomplete recovery (across any group); it’s obvious this isn’t the case. However, I’m not prepared to endorse the idea that the policies his government pursued had no impact on its trajectory– that’s a question of degree I’m not confident I can answer here.
Anyways, given that more waves are available, we don’t have to look at a single comparison between 2007 and 2016, if we want to push Bruenig’s work a little further. The SCF is conducted every 3 years (typically), so we can add two more lines to Bruenig’s graphs to look at 2010 and 2013 as well. Bruenig mentioned on Twitter that the overall patterns came out the same, but I decideded to dig into this on my own as a learning exercise. I’ve downloaded each of the typical waves of SCF data (Summary Extract Public Data Files from 07-16), and pulled out the relevant variables to recreate Bruenig’s plots. I present the code I used to analyze them in R below if you want to follow along, but if uninterested you can skip down to the graphs below.
drawing some additional lines
library(tidyverse)
library(scales)
library(reldist)
library(plotly)
# plotting theme
theme_set(
theme_minimal(base_size = 14) +
theme(
panel.grid.minor = element_blank(),
legend.position = "bottom",
legend.title = element_blank()
)
)
# pull in the data and prepare the categorical variables for plotting
scf <- read_csv("../../static/data/scf-reanalysis/scf-0716-networth.csv")
scf$year <- factor(scf$year)
scf$race <- factor(scf$race, levels = c("White", "Black", "Hispanic", "Other"))We’re interested in the percentile values for each race/ethnicity, across each wave of the survey. Given that we’re working with samples (whose composition changes slightly between waves), the percentiles should be adjusted based on the weights provided in the data. The reldist::wtd.quantile() function extends R’s standard quantile() function to allow us to take them into account.
# creates a data_frame with a year/race for each row, with the 100 percentiles
# stored as a list column
pctles <- scf %>%
group_by(year, race) %>%
do(networth = wtd.quantile(.$networth, seq(.01, 1, .01), weight = .$wgt))
# do() returns the results as a rowwise data_frame, but we want to pull out
# all the observations from the lists and stack them; unnest() gets us there
pctles <- pctles %>%
group_by(year, race) %>%
unnest(networth) %>%
mutate(pctle = 1:length(networth)) %>%
ungroupNow that we’ve generated the percentile values for each group * year combination, we can move on to generating the values being displayed in each plot. We’re looking at the difference between a given year’s percentile values to its corresponding estimate in 2007. Thus, we’re not looking at a year-by-year change, but we’re comparing each year’s position relative to what was recorded in 2007 (just prior to the onset of the Great Recession). The code is accomplishing this somewhat differently, but you could imagine having a spreadsheet with exactly 100 rows, and a column for each year. Each row would contain the value for net worth at a given percentile, and the quantities of interest will be represented as 3 additional columns: column 2007 - column 2010; column 2007 - column 2013; and column 2007 - column 2016.
# now we want to take the difference between each wave's values from the 2007
# estimates, making sure we're comparing estimates within race/pctile
pctles <- pctles %>%
group_by(race, pctle) %>%
arrange(race, pctle, year) %>%
mutate(
diff = abs(first(networth) - networth), # absolute difference
diff = ifelse(networth < first(networth), -diff, diff) # increase or decrease?
) %>%
ungroupThis gives us a “tall” data file that’s structured like this:
| year | race | networth | pctle | diff |
|---|---|---|---|---|
| 2007 | White | -36245.87 | 1 | 0.00 |
| 2010 | White | -86436.71 | 1 | -50190.84 |
| 2013 | White | -85787.91 | 1 | -49542.04 |
| 2016 | White | -71400.00 | 1 | -35154.13 |
Next, we can rebuild the plots. Let’s start by looking at the change in white wealth. Unlike Bruenig’s, these will contain additional lines, allowing us to compare 2010 and 2013 to the 2007 values, in addition to the most recent data from 2016.
My expectation was that we’d see a fairly strong correlation between the waves, which mostly plays out for the bulk of the distribution. The basic curve/shape of the lines seem consistent, except when you creep up to the 97-99th percentiles. As best I can tell, it seems like recovery for the top 3% didn’t really start to pick up until after 2013. This feels sort of surprising to me; my expectation was that the super high percentiles (96-99) would have ridden things out a little better. It looks as if upper-class white families experienced the sharpest downturn closest to the 2007, but we start to see some recovery between the waves in 2013. Lower- and middle-class whites (i.e. percentiles 0-65~) generally dropped about as far as they would by 2010, where they continued to sit until 2016.
Shifting to black families, we see a slight difference in that the worst declines for families above the median are observed between 2010 and 2013. It looks as if families above the median only really recover to a little above where they were in 2010. The top-10% in this group appears more like what I expected, in that the 98-99th percentiles seem to fair better than those between 90-97.
Lastly, looking at Hispanic/Latino wealth, we see a similar pattern to the previous group in that the upper-middle class suffers a fairly steep decline, although it looks like 97-99th percentiles weren’t really able to avoid the worst effects of the recession, and don’t improve until 2016.
relative differences
Having looked at the absolute differences across each group, I wanted to dive deeper on the differences between 2013 and 2016. A 1.2 million dollar swing seems like a lot to me, but perhaps it’s better to place that in the context of how much the higher percentiles actually have. Additionally, I wanted to see how things changed for the rest of the distribution, given that their absolute differences are being minimized on the scale of the initial plots. I’ve reworked the three preceding plots, but instead of displaying the raw difference from each percentile’s 2007 value, we’re looking at that difference expressed as a percentage of the 2007 net worth.
For ease of interpretation, I’ve snipped off the bottom quarter of the percentiles. Many of these had net worths approaching 0 (or below), and quite a few ended up reflecting large drops into debt, showing up as really steep drops that distort the rest of the range. In brief, it’s safe to say that if you already had very little to begin with, the recession was excruciating. However, you can see this reflected in how the lower end of the range also shows the greatest declines across each wave.
The switched measure also allows us to look closer at some of the patterns we saw above. For white families, you can see how their status generally stayed the same between the 2010 and 2013 waves, and didn’t recover until 2016.
But when you look at black and Hispanic/Latino families, we get a clearer look at this sort of delayed decline that we pick up in the 2013 wave, which is more pronounced for black families. Homes have historically been one of the most reliable repositories for American wealth; a lot of research has already been done about how black families were especially affected by forclosures. From what I’ve read, housing forclosures peaked in 2010, and while declining, were still high common up through the 2013 wave. Something else we can see more clearly is how relatively worse off black families are compared to whites and Hispanics/Latinos; both of these groups appear to have turned a corner in 2016, even if they aren’t all improving from where they were in 2007.
the traditional approach
Lastly, I decided to loop back and lay out the more traditional presentation. A reasonable criticism might be that percentiles don’t work as a continuous scale; the space between each rank isn’t regular, and thus using a line might misleadingly imply regular progression. Based on the data we have, it’s simple to invert the presentation, and use the multiple waves of the survey to reflect change over time. Yet, it seems we have a new problem: can we still show the variability across all the percentiles? Including 100 individual lines in each panel feels way too busy. I opted for plucking out a handful of deciles (dropping the 10/20th percentiles, given their drops fall below the y-axis’s limits), as well as the 25th, 95th, and 99th percentiles. Having looked at 3 different ways of approaching these data, I feel like the claim in the title of Bruenig’s post generally holds up. This last presentation might be most respectful to the fundamentals, but feels a little disappointing, given we’re stuck leaving a good amount of the data out in order to be concise.
wrap up
I think I’ve matched the spirit of Bruenig’s approach, and ideally expanded on the original presentation. The basic takeaway for the most recent data seems the same, in that black and Hispanic/Latino families experienced enduring losses of wealth amongst their middle class, whereas whites above the 75th percentile are making some strong gains.
I think it’s also worth noting that for both white and Hispanic/Latino families, you can see a really sharp climb between 2013 and 2016 among the highest percentiles. This trend seems more gradual in the plot for black families. I know recovery from the financial crisis has been slow, but I wonder why the shift only appears in the last few years, even among the wealthiest. Maybe this is an artifact? Perhaps I’m using the weights incorrectly, or missed something else? If so, feel free open an issue to help me fix it!